My recreational programming in 2024: Mostly Standard ML
The year in review
2024-12-15
To the extent that lack of free time permits, I try to do some recreational programming on the side, unrelated to my dayjob or any money-making concerns. I find it helps me retain some love for the subject matter, and keeps me sharp.
In the past year, I’ve gotten into Standard ML programming, using the excellent PolyML compiler, and got a bunch of tiny projects done. The approach I took was simple: just code. I consciously avoided getting into any kind of ‘industrial’ concerns, such as resuability, open-source contribution, etc. The idea was to simply produce a bunch of code and have fun doing it. Below is a list of fun things I built this year, with some reflections:
1. The assert testing library for PolyML
As I started out programming my little Standard ML projects, the first issue I ran into was the lack of quick-and-easy testing tooling. Yes, there is SMLUnit, but I find its approach too bureaucratic and ponderous for my taste. I wanted something that would let me 1) write a lot of tests easily without boilerplate; 2) provide readable output for tests results, without me having to define custom printing functions.
While the first requirement was subjective and easy to fulfill, the second one
immediately posed problems, due to the fact that there is no standard interface
to print arbitrary data in Standard ML. I find this to be an ironic situation,
since most Standard ML environments provide a REPL, which does indeed know
how to print out arbitrary data. Luckily, PolyML exposes its ad-hoc printing
machinery as PolyML.makestring (although it must be called explicitly as
PolyML.makestring – any kind of aliasing causes the magic to break), so I
decided to let that fact guide me and focused my Standard ML programming on
PolyML only. Ultimately, I think this was a good thing, as trying to make my
code standards-compliant and compatible with all Standard ML implementations
represented exactly the kind of ‘industrial’ busywork that I wanted to avoid.
About the library: there were a couple interesting things related to API design which did not strictly involve pretty-printing arbitrary data. First of all – what should be the type of a test? The simplest idea would be something like:
type testcase = (unit -> bool)
which would allow us to write tests of the form:
> val t1 = (fn () => 2 + 2 = 5) : testcase;
> t1 ();
val it = false: bool
This is sufficient to get going, but eventually one would like to see exactly
which tests failed in a batch, and getting a list of results such as [true,
true, true, true, false, true, false, true] is not great developer experience.
So the next ‘easy’ thing would be to label our testcases so the runner could
refer to them:
> type testcase = string * (unit -> bool)
> val t2 = ("two and two make five", fn () => 2 + 2 = 5): testcase
> (#2 t2)();
val it = false: bool
This is better, as now our hypothetical test runner can tell us which test failed. But it would still be nice to see the value which caused the test to fail. And so it’s at this point that we need to break out the pretty-printing. How would we design a testcase that prints out failed arguments? Maybe something like this?
> type testcase2 = string * (unit -> string option);
> val t4 = ("two and two make five", fn () =>
> (if 2 + 2 = 5
> then NONE
> else SOME (Int.toString(2+2)))) : testcase2;
> (#2 t4)();
val it = SOME "4": string option
Okay, now we have a better informational API, but the test body itself has become incredibly unwieldy. We can try to extract the display function and only use it on a failing value … but that makes our test case typing much more involved. Something like this perhaps?
> type ''a testcase3 = string * (''a -> string) * (unit -> ''a option);
> fun runtestcase (desc, pp, testfun) =
> case testfun () of NONE => (desc ^ " passed")
> | SOME v => (desc ^ " failed: " ^ (pp v));
> val t5 = ("two and two make five",
> Int.toString,
> fn() => if 2 + 2 = 5 then NONE else SOME (2+2));
> runtestcase t5;
val it = "two and two make five failed: 4": string
Okay, that reduced some of the machinery, but we still have to provide the failing value in the test body. It would be nice to extract this mechanism also. Maybe with an assertion function such as the following:
> fun assertEqual (got: ''a, expected: ''a, pp: ''a -> string) : string option =
> if got = expected then NONE else SOME (pp got);
That lets us remove the ''a out of the testcase type and allows us to mix
test-cases asserting on different types again:
> type testcase4 = string * (unit -> string option)
> val tests = [ ("int addition", fn () => assertEqual(1+1, 3, Int.toString)),
("concatenation", fn () => assertEqual("a"^"b", "abc", fn x => x)) ];
> map (fn (desc,t) => (desc, t ())) tests;
val it = [("int addition", SOME "2"), ("concatenation", SOME "ab")]:
(string * string option) list
This is nice, but for maximum usability, we’d like the test framework to do all our pretty-printing for us, since there is no built-in pretty printer even for a list of ints, much less for any user-defined datatypes. Also, it would be good to test for non-equality and for exceptions thrown, and to have all the data that we assert on printed out in the test log.
To that extent, I ended up with a test structure which exposes test case constructor functions as well as test assertions, and leverages the type system to give you confidence that a test case must contain an assertion and cannot silently pass.
So, for example, here is a list of tests asserting that Base64 decoding errors are thrown by the Base64 library under test:
val errorTests = [
It "bails out when input is ascii but not from the base64 set" (
fn _=> (B.DecodeError "Input not Base64") != (fn () => B.decode "!@#%")
),
It "bails out when input is too short" (
fn _=> (B.DecodeError "Invalid/incomplete sequence") != (fn () => B.decode "a")
),
It "bails out on non-ascii input" (
fn _=> (B.DecodeError "Input not ASCII") != (fn () => B.decode "Żółw")
)
]
Note the use of the != assertion, which takes an Exception on the left and
a thunk on the right, and asserts that the thunk throws the exception when evaluated.
Here are some tests of the example text from the Base64 wikipedia entry:
val exampleDecodingTests = [
It "decodes the wikipedia example: Man" (
fn _=> B.decode "TWFu" == Byte.stringToBytes "Man"
),
It "decodes the wikipedia example: Ma" (
fn _=> B.decode "TWE=" == Byte.stringToBytes "Ma"
),
It "decodes the wikipedia example: M" (
fn _=> B.decode "TQ==" == Byte.stringToBytes "M"
)
];
The provided test runner lets us run all the tests we defined like so:
fun main () = runTests ( exampleEncodingTests
@ paddingTests
@ exampleDecodingTests
@ errorTests
@ roundTripTests)
If we modify one of our tests to fail
It "decodes the wikipedia example: Ma" (
fn _=> B.decode "TWE=" == Byte.stringToBytes "Maxx"
),
and run the test suite with poly, we get:
FAILED decodes the wikipedia example: Ma
fromList[0wx4D, 0wx61] <> fromList[0wx4D, 0wx61, 0wx78, 0wx78]
TESTS FAILED: 1/17
make: *** [Makefile:6: test] Error 1
I’m quite happy with this design and I consider it the only one that’s
“production ready” from among this year’s recreational projects. It’s a
one-file library, and including it in your code is as easy as opening
Assert. I used it in all my subsequent Standard ML codebases.
2. A Base64 encoder/decoder
I took on this project to answer the question of just how much speed one can expect of Standard ML with real-world tasks, such as text encoding.
It turns out that naively implementing the logic leads to very poor performance, primarily caused by massive memory churn on allocations and deallocations of intermediate datastructures. I took a look at various other implementations and found that the SML/NJ algorithm was blazing fast.
Here is my benchmark with Poly/ML used to compile and run the algorithms:
/bin/time ./bench b # My algorithm
8.17user 1.82system 0:08.06elapsed 124%CPU (0avgtext+0avgdata 210612maxresident)k
0inputs+0outputs (0major+198647minor)pagefaults 0swaps
/bin/time ./bench s # sml/nj algorithm
0.88user 0.38system 0:01.28elapsed 99%CPU (0avgtext+0avgdata 20936maxresident)k
0inputs+0outputs (0major+43224minor)pagefaults 0swaps
And here is the same benchmark run under mlton:
/bin/time ./bench b # my algorithm
1.88user 1.60system 0:03.52elapsed 99%CPU (0avgtext+0avgdata 535832maxresident)k
0inputs+0outputs (0major+180440minor)pagefaults 0swaps
/bin/time ./bench s # sml/nj algorithm
0.34user 0.12system 0:00.47elapsed 98%CPU (0avgtext+0avgdata 47344maxresident)k
0inputs+0outputs (0major+13291minor)pagefaults 0swaps
Some interesting things to note: 1) simply using mlton to compile your code
gives you a 4x speed improvement for the exact same task; 2) Using mlton to
produce the ‘release’ version of your code, while leveraging polyml for quick
compilation & test-turnaround is exactly the kind of ‘industrial’ activity I
wanted to avoid, but the polybuild guy has put together some nifty
harnesses to make it doable; 3) ultimately, any string-mangling you end up
doing in Standard ML is going to get smoked by python (because it calls out
to c):
/bin/time python3 ./test/bench.py
0.09user 0.02system 0:00.12elapsed 99%CPU (0avgtext+0avgdata 15484maxresident)k
0inputs+0outputs (0major+5731minor)pagefaults 0swaps
and smoked all the worse by the gnu coreutils:
/bin/time base64 ./bytes > /dev/null
0.00user 0.00system 0:00.00elapsed 25%CPU (0avgtext+0avgdata 1920maxresident)k
96inputs+0outputs (2major+108minor)pagefaults 0swaps
So the outcome of this experiment was not super encouraging – even the best-written algorithm, compiled with a powerful sci-fi compiler, still loses out to the python stdlib. On the other hand, I had a fun time testing and implementing a well-known standard, so I got my kicks nonetheless.
3. Sqlite3 FFI binding for PolyML
This project was very educational, rewarding, and just plain fun. I actually
started working on it on my wife’s computer during our family trip to Japan.
With only emacs, the sqlite3 documentation, and the PolyML source and docs, I
was able to put together a basic but functional sqlite3 library, complete
with a reliable test suite.
I don’t have much commentary here. I somehow plodded through the various components based on trial-and-error, trying to figure out how the outdated PolyML FFI tutorial relates to the current FFI implementation. Ultimately, I was able to work things out based on the PolyML source code.
Here are a couple of the tests I eneded up writing:
It "can read a row (unicode literal)" (
fn _=>
let val db = givenTable "create table f (a int, b double, c text)";
val _ = S.runQuery "insert into f values (?,?,?)" [
S.SqlInt 1,
S.SqlDouble 2.0,
S.SqlText "こんにちは、世界"] db;
val res = S.runQuery "select * from f" [] db;
val _ = 1 =?= length res
in case hd(res) of
[S.SqlInt 1,
S.SqlDouble _,
S.SqlText "こんにちは、世界"] => succeed "selected"
| other => fail ("failed:" ^ (PolyML.makestring other))
end),
It "returns proper codes on constraint violation" (
fn _=>
let val db = givenTable "create table f (a int)"
val r0 = S.SQLITE_OK =?= (S.execute "create unique index fi on f (a)" db)
val r1 = S.SQLITE_OK =?= (S.execute "insert into f values (1)" db)
val r2 = S.execute "insert into f values (1)" db
in r2 == S.SQLITE_CONSTRAINT
end)
4. Serpent Encryption in Standard ML
“Where is this all going?”, you might ask. All of the above components actually were supposed to build up to a working client of a certain p2p chat protocol – the one that posits using Serpent, the runner up to the AES spec.
This project, like the sqlite3 library, had me streching myself to work in a domain which I’m not super familiar with. (don’t roll your own crypto, they said). Aside from whatever difficulty was inherent in the problem domain itself, I had to do a bit of online archaeology to ensure I’m implementing the right thing. A good test library (as implemented by me) helped a lot with making sure I wasn’t regressing, but the bulk of the work consisted in finding working implementations of Serpent and ensuring mine was compatible.
This was not as easy as it sounds, as Serpent is mostly forgotten, but there are several implementations floating around: the original NIST implementation and its variants, some educational variants, and some free-floating c libraries. Endianness problems abound with the NIST data going one way, regular usage going another. Some implementations do CBC, others don’t. Etc, etc.
Long story short, I was able to get an implementation working, which, despite having a messy interface, is quite performant and well-tested. I sure as hell wouldn’t encrypt anthing sensitive with it, but it meets the spec. It does CBC.
I had a lot of fun implementing the Osvik S-boxes, even going as far as to recreate the table layout in the sml code:
|  |
I think this is one of those instances where Standard ML’s facility with
defining new operators proved to be a big benefit. After defining the mutating
operators ^=, &=, |=, and =~, I was able to follow along with the paper
and mechanically input the paper’s original syntax into my code.
5. Roguelike etudes
This is not a notable project by any means, but it was just me trying to put together a bunch of little toy programs without getting bogged down in detail. Despite actually writing a playable roguelike being a dream of mine since high school, I didn’t achieve much in this regard.
I did spend some time programming the toys with my kids. They provided me the impetus for adding a bit of visual flair, taking my version of 2048 from this:

To this:
To this:
Although nothing resembling a rogulelike emerged from this project, it provided fun for me and the kids. Standard ML turned out to be a nice lanague for this type of toy.
6. Working through “ML for the Working Programmer”
I did a bunch of exercises from the first half of this book. They are quite hard, but rewarding. To aid my understanding, I ended up writing little utilities to visualize the data structures involved.
Standard ML actually makes it quite easy to interact with POSIX-world, and with a few functions such as:
type cmdBuilder = (string -> string list);
fun page tmpfile =
["(dot -Tpng ", tmpfile, " | 9 page -R)"];
fun save tmpfile =
["dot -v -Tpng -ooutput.png ", tmpfile ];
fun drawTree (fmt : 'a -> string) (cmd : cmdBuilder) (t : 'a tree)
: Unix.exit_status =
I was able to visualize all the structures that were being manipulated in the section on trees and functional arrays. That allowed me to take this tree:
> tree4;
val it =
Br
(4, Br (2, Br (1, Lf, Lf), Br (3, Lf, Lf)),
Br (5, Br (6, Lf, Lf), Br (7, Lf, Lf))): int tree
> drawTree Int.toString page tree4;
And get this graphic:
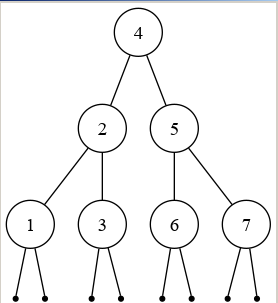
This really helped when the structures got large and complicated. In general, working on this book made me appreciate how, when learning new topics, it helps to ‘see’ them from multiple perspectives. Being able to see the subject matter in graphical form made it interesting even for my kids.
My interest in Standard ML slowly petered out as I was working on this book. I realized that trying to get a ‘real’ project off the ground will require the kind of ‘industrial’ thinking that I’d been avoiding throughout. It would mean integrating various 3rd-party libraries and getting them to build together, deciding on module dependency structures, building smlnjlib on polyml, etc. That kind of stuff not qualifying easily as “recreational programming” in my book, I decided to try something else next.
7. Classic Computer Science Problems in Python
Since I use Python at work, I figured it wouldn’t hurt to do some recreational coding in it. I picked this book based on Amazon suggestions and Henrik Warnes’s review. I’ve completed six out of nine chapters and feel I’ve gotten a good refresher on classic CS, along with some new Python tricks up my sleeve.
Like Henrik, while I have some misgivings about this or that aspect of the book, I recommend it to colleagues as a high-density refresher on the kinds of things you probably don’t work on at work.
8. Other loose ends
Several friends have asked me whether I’m doing Advent of Code this year. The short answer is: I love the idea and implementation of Advent of Code, but the timing is so cruel as to be sadistic. In the run-up to Christmas, it’s really hard to get an hour a week to devote to recreation programming, much less an hour a day.
Good luck to all of you who are participating this year!